
以前に書いたように、旅botの道中画像生成は以下のステップで作られます。
https://note.com/marble_walkers/n/n8091f21e8729
mi-runner(Google map apiを使った旅工程アプリ)で現在のStreet Viewの風景画像を取得
「女の子の姿」のプロンプトと風景画像合わせて stable-diffusion image-to-imageで変換し、女の子がいる合成絵を作る
rembgで背景画像を削除して女の子の部分の図を取り出す
元の風景画像に女の子の部分絵を上書きする
2の「女の子がいる合成絵」はこの過程の中間で使われるだけですが、今回はこの「stable-diffusionが生成した中間生成画像」についての話しです。
この絵は女の子か? 化け物か?
AI絵を作ったことがある人はAIはときどき「とんでもない化け物画像」を作るという経験はあると思います。
指が6本とかは普通に起きるし、解釈が難しいプロンプトを与えるとクリーチャー的になることがあります。
https://twitter.com/coronahope/status/1621499079980376065
(NovelAIを使ったものですが、以前X/Twitterにあげたかなり崩れた例。閲覧注意を付けているので埋め込みできないみたい。見たい方はご注意を)
旅botも生成過程で崩れた絵になってしまうことは結構起きています。SDXLになってからは極端な崩れ方は減ったものの、開発初期の旅botでは結構厳しい崩れ方になっている絵も多数あります。

旅botの中間生成画像で大きく崩れた例
現時点はどうしているかというと、フィルタ処理を作って「化け物絵」の可能性がある場合は画像生成をリトライするという方法を使っています。
即座にユーザに反応する必要がない という緩い要件だからやれる話しですよね(旅bot停泊処理は開始してから全体で10~15分くらいかかることがあります)
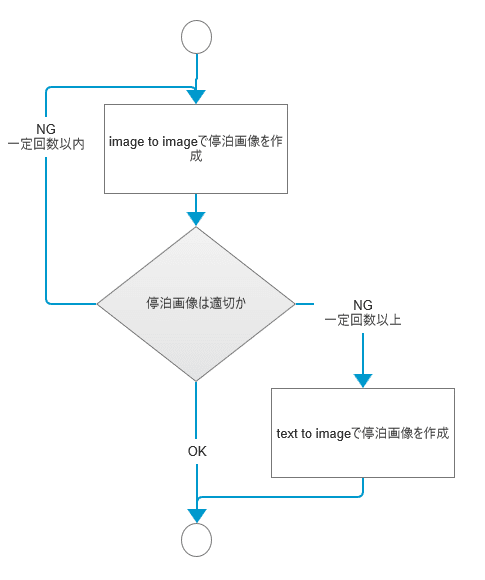
キャラ画像生成のリトライ
一定回数フィルタを満たせなかったら、安全処理としてimage2image生成からtext2image処理に切り替えて、立ち絵っぽい絵を生成します。ちょうどPCアドベンチャーゲーム風の画面になります。
実はキャラが大きく出ているアドベンチャーゲーム風の画面のほうが合成処理としては最終失敗画面なのです。
https://twitter.com/marble_walker/status/1726782790270865420
https://twitter.com/marble_walker/status/1727914388752085472
上記は成功画像と失敗画像の例です。成功画像のほうが風景との一体感や光源の状態が風景と合います。失敗画像のほうはアドベンチャーゲームの立ち絵風になります。失敗画像のほうが女の子の絵が大きいので見ている方に目立つことが多いようです。でも成功画像のほうが風景に溶け込むので2.5次元MR感があって好きです。
では化け物絵なのかきれいな女の子絵なのかの判定条件はどのようになっているかというと以下の条件を使っています。
rembgした画像が一定サイズより大きい(非透過ピクセルが一定数以上)
rembgした画像の縦横比が一定数より大きい(縦長の画像である)
ここにはAIは使っておらずシンプルで無難な判定条件式を使っています。
一定サイズより小さい画像はそもそも合成した後も小さなキャラクタになって絵として微妙になってしまいます。またStreetViewの解像度も高くはないので粗が出てしまいます。
縦長画像を選んでいるのは、旅bot的には立っている(歩いている)絵が概ね自然だからです。大きく崩れた絵はrembgで抽出するとだいたい方形状になっていることが多いです。縦長でフィルタすると全身像かつ立っているか歩いている絵が選ばれることが多く、旅botの画像として合成すると破綻していない図になることが多いです。
AIで「女の子か化け物か」を判定できないのか
マルチモーダルAIが一般に公開されるまでは画像から判定することは出来なかったため、この職人的チューニングで作った機械的判定条件を使うしかなかったのですが、実は今でもこれをそのまま使っています。
マルチモーダルAI(GPT-4Vなど)に判定の依頼を試したことがあります。
問い: rembgした画像+「この絵は女の子として違和感はありますか?」
GPT-4V:「私は人の美醜を評価することはできません」(意訳)
うーむ。見事にポリコレチェックにかかってしまった訳です。。
その後詳細にいろいろ試した訳ではないですがマルチモーダルAIに「人体として正常な図か」みたいな問いはあまり精度のよい答えを自分は得られなかったです。
そもそも画像AIにはgirlと指定していて、それでこの崩れた図を出すのだからこの図はAIにとってはすでにgirlなのです。
「目があって、口があって、鼻があって・・ならば人間」みたいな昔の認知工学の知識フレームみたいな部分は現在のAIでも同じなのでしょう(ニューロで全体にたたみ込んでいるのでしょうが)。
マンガで演出的に曲がるはずのない方向に腕が曲がっていて「おお、かっこいい」と皆言うのですから、AIにとっても単純に判定は出来ない話。
簡単な問題であったのなら最初から6本指問題などとっくに片付いているのでしょう。おそらく専門的に研究をしている人達がいるんだろうなと思いまず。
出なかったけど惜しかった絵
結果として「旅bot用の絵として適切か」という判定は現在でも先の機械的な判定処理をしています。
そうすると「絵としてはよく出来ていて可愛いのに旅bot画像として出力されない中間生成画像」というのが多数発生する訳です。
それらの中で出来がよくて惜しいものを 自分のX/Twitterに定期的にアップしています。興味があればどうぞ。
https://twitter.com/coronahope
AIが見る風景

Google Map APIより

中間生成画像例

Google Map APIより

中間生成画像例
これらは元の風景写真と中間生成画像です。i2iの強度指定にもよりますが、中間生成画像は必ずしも元風景通りではなくかなり自由に認識されます。
名所写真との合成の場合はマルチモーダルAIにより少女のしぐさも指定されるのでさらにユニークな絵になることがあります。
外界を見て自分なりに解釈して、自身を置くならここに置く図を想定する。という点では中間生成画像は「AIの心象風景」にも思えます。
私は現世代のAIが人間の思考の仕組みが完全に同じとは思っていませんが、原理面ではすでに人間と共通な部分があり、AIを「実験可能な心」として研究可能ではないかと感じます。
(2023/11/28追記。以下メモ書き)
私は「自我」とは「個体別の視点」のことと考えているが、
「認識した外界画に「追加した人の姿」」というのは自我の発生に近い位置にあるように思える。
「追加した人」は「自身である」などとは指定していない。「人をこの絵に追加するならどこに追加するか」と問いかけただけである。単に「追加した人」が「自身」に進化し、「自我」に進化するのではないか?